


软件测试培训
达内IT学院
400-996-5531
400-996-5531
大量的数据散落在互联网中,要分析互联网上的数据,需要先把数据从网络中获取下业,这就需要网络爬虫技术。
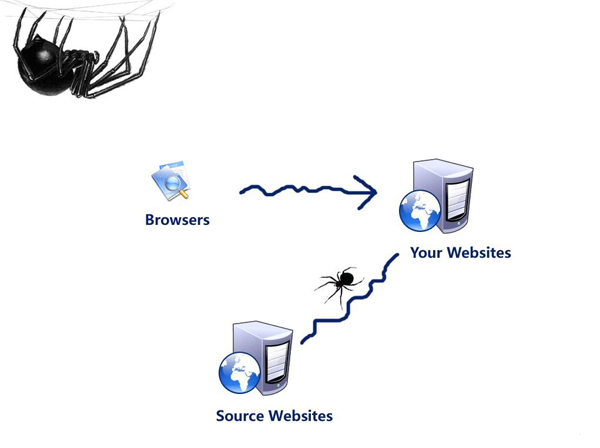
网络爬虫是搜索引擎抓取系统的重要组成部分,爬虫的主要目的是将互联网上网页下载到本地,形成一个或联网内容的镜像备份。
网络爬虫的基本工作流程如下:
1.首先选取一部分种子URL
2.将这些URL放入待抓取URL队列
3.从待抓取URL队列中取出待抓取的URL,解析DNS,得到主机的IP,并将URL对应的网页下载下来,存储到已下载网页库中,此外,将这些URL放入已抓取URL队列。
4.分析已抓取到的网页内容中的其他URL,并将URL放入待抓取URL队列,从而进入下一个循环。
填写下面表单即可预约申请免费试听! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可全国推荐就业!



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



